FlagOS 概览#
FlagOS 是一个完全开源的异构 AI 芯片系统软件栈,允许 AI 模型一次开发即可无缝移植到广泛的 AI 硬件平台,实现最小化的适配成本。
FlagOS 架构#
下图展示了 FlagOS 在 AI 生态系统中的位置及其组成模块。
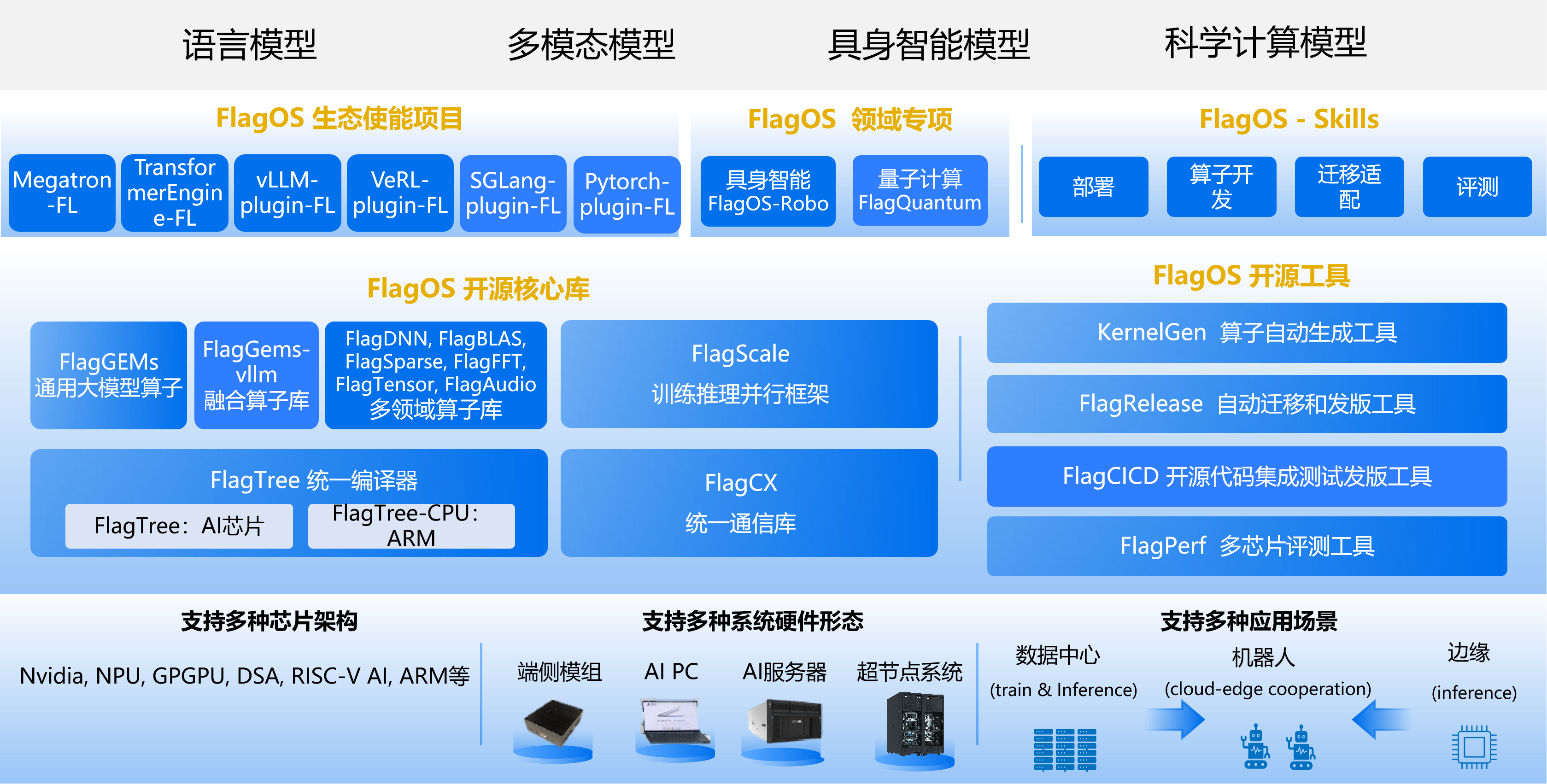
FlagOS 2.1 包含以下核心库、插件、领域专用项目、开发者工具和平台服务。
开源核心库#
算子库
通用算子库
FlagGems (v5.3.0)
FlagGems 是一个使用 Triton 编程语言及其扩展语言实现的高性能通用算子库。FlagGems 旨在为大模型提供一套通用算子,加速多后端平台上的模型推理和训练。
融合算子库
FlagGems-vllm (v0.1.0)
一个面向多硬件后端的高性能算子库。它提供常见 vLLM 算子的优化实现,支持多种广泛使用模型的高性能推理和部署。
多领域算子库
FlagDNN (v0.2.0)
一个面向多芯片后端的深度神经网络计算库。它提供常见深度学习算子的高性能实现。
FlagBLAS (v0.2.0)
一个遵循 BLAS 标准接口、面向多芯片后端的计算库。它定义数值计算的核心操作。
FlagFFT (v0.1.0)
一个 JIT 编译的 GPU FFT 库。它通过 Triton/TLE 和 libtriton_jit 在运行时生成 CUDA 内核,针对 cuFFT 无法最优支持的任意长度变换。
FlagSparse (v0.2.0)
一个领域专用算子库,包含专门用于稀疏计算场景的算子。
FlagTensor (v0.2.0)
一个使用 Triton 语言实现的高性能张量原语库。它提供常见张量原语(一元、二元和张量缩并操作)的优化实现,并以 cuTensor 为基准进行测试。
FlagAudio (v0.2.0)
一个遵循 Audio 标准接口的多后端计算库。它为音频信号处理和语音 AI 应用提供高性能计算解决方案。
FlagTree (v0.6.0)
FlagTree 是一个开源的多 AI 芯片统一编译器。FlagTree 致力于为多样化的 AI 芯片构建编译器及相关工具平台,推进和扩展 Triton 上下游生态系统,目标是支持现有适配方案、统一代码仓库,并实现从单一仓库快速支持多后端。对于上游模型用户,FlagTree 提供跨多后端的统一编译支持;对于下游芯片厂商,FlagTree 提供集成到 Triton 生态的参考实现。
FlagScale (v2.0.0)
FlagScale 是一个全面的大模型全生命周期工具集。FlagScale 基于 Megatron-LM 和 vLLM 等多个知名开源项目的优势,为管理和扩展大模型提供稳健的端到端解决方案。
FlagCX (v0.13.0)
FlagCX 是一个可扩展、自适应的跨芯片环境统一通信库。FlagCX 为多芯片、多平台场景提供高性能的点对点和集合通信能力。通过利用每个平台的原生集合通信能力,FlagCX 采用设备缓冲区 IPC 和 RDMA 等技术,在跨芯片和单芯片场景中实现高效的集合通信,同时提供通信优化的自适应调优能力。
插件#
FlagOS 生态使能层采用插件架构,由以下模块组成。每个模块将上游库及其后端引擎与 FlagOS 核心库连接起来。
vllm-plugin-FL (v0.2.0)
vllm-plugin-FL extends the inference capabilities of vLLM to diverse AI chips, enabling efficient model serving beyond the original supported hardware. Built on FlagOS’s unified multi-chip backend.
sglang-plugin-FL (v0.1.0)
sglang-plugin-FL 是 SGLang 的一个树外 (OOT) 插件,基于 FlagOS 的统一多芯片后端构建。它将 SGLang 的推理能力扩展到多种硬件平台。
PyTorch-Plugin-FL (v0.1.0)
PyTorch-Plugin-FL 是一个基于 PrivateUse1 扩展机制的自定义 PyTorch 设备插件,将 FlagGems 高性能 Triton 算子注册为 flagos 设备后端,实现统一的多芯片支持。
Megatron-LM-FL (v0.2.0)
Megatron-LM-FL 将 Megatron-LM 的分布式训练能力扩展到多种 AI 芯片,支持跨异构硬件的可扩展大模型训练。
TransformerEngine-FL (v0.2.0)
TransformerEngine-FL 将 Transformer Engine 的 transformer 加速能力扩展到多种 AI 芯片,实现硬件无关的训练加速。
verl-FL (v0.2.0)
verl-FL 将 veRL 的强化学习能力扩展到多种 AI 芯片,拓宽基于强化学习训练工作流的硬件覆盖范围。
vllm-plugin-FL、Megatron-LM-FL、TransformerEngine-FL 和 verl-FL 可以与 FlagScale 配合使用。当只需要一两项能力(如训练、推理或强化学习)时,相应模块可以独立地将其上游库和后端引擎与相关 FlagOS 核心库模块连接,提供满足多样化用户部署场景的灵活性。
领域专用项目#
FlagOS-Robo (v0.1.0)
FlagOS-Robo 是一个芯片无关的框架,用于在具身智能的端到云场景中训练和部署视觉语言模型 (VLM) 和视觉语言动作模型 (VLA)。它将 VLM 视为任务规划的"大脑",将 VLA 模型视为生成机器人控制动作的"小脑"。
FlagQuantum (v0.1.0)
FlagQuantum 是一个基于 PyTorch 构建的高性能分布式量子态矢量模拟器,支持跨多 GPU 的量子电路模拟,具有自动分片和重新分片功能。
开发者工具#
KernelGen (v2.1.0)
KernelGen 是一个算子自动生成工具。KernelGen 旨在通过自然语言提示构建算子定义,检索现有相似算子定义,自动执行算子精度和性能测试,生成精度和性能测试结果,并产出 Triton Kernel。
FlagOS Skills (v1.1.0)
FlagOS Skills 是与 Agent 兼容的能力集,旨在简化关键 FlagOS 工作流程,包括部署、算子开发、迁移、适配和性能评估。兼容 Claude Code、Cursor、Codex 以及任何支持 Agent Skills 标准的 Agent。
线上实验室
一个为 FlagOS 项目提供云端开发环境的线上实验室。
平台服务#
FlagRelease (v0.1.0)
FlagRelease 是一个致力于多架构 AI 芯片大模型自动迁移、适配和发布的平台。FlagRelease 旨在通过自动化、标准化和智能化的适配工作流程,使主流大模型能够以更低成本、更高效率在多样化国产 AI 硬件上完成迁移、验证和发布。
FlagPerf (v1.2.0)
FlagPerf 是一个集成的 AI 硬件评测引擎。FlagPerf 旨在建立业界实践导向的指标体系,评估 AI 硬件在软件栈组合(模型 + 框架 + 编译器)下的实际性能。
FlagCICD (v0.1.0)
FlagCICD 是一个 CI/CD 工具链,简化跨多种 AI 芯片的大模型开发,消除碎片化并降低适配成本。
KernelGenBench (v0.1.0)
KernelGenBench 是一个基准测试框架,用于评估跨多硬件平台的 LLM 和 Agent 驱动的 Triton kernel 生成能力。